ディープラーニングとは

Incubit Blog Team
目次
ディープラーニングとは?
ディープラーニング(深層学習)とは、機械学習の一種です。大量のデータを使ってコンピューターを学習させることで、物事の特徴やパターンを抽出し、特定の判断や予測に役立てることができる技術になります。
たとえば大量の手書き文字を読み込ませ学習させることで、自動で手書き文字を認識できるシステムを作る、猫の画像をもとに学習させたコンピューターによって画像内の猫を自動で識別する、といったことがディープラーニングによって可能になります。
コンピューターの性能の向上や、学習の元となるビッグデータ技術の普及といった様々な要因により、2010年代に入ってから実用化が進んだ技術です。IBMのワトソンが米人気クイズ番組「ジェパディ!」にチャレンジしたことや、ディープラーニングを用いて開発されたコンピューター囲碁プログラム「AlphaGo」(アルファゴ)が、2015年にプロの囲碁棋士を破ったことなどをきっかけに、一気に世間の注目を集めました。
「大量のデータから特徴やパターンを抽出し、何らかの判断や予測に役立てることができる」という汎用性が高い技術のため、あらゆる分野で活用され得る可能性を秘めています。またコンピューターを学習させるためのデータの種類も、画像やテキスト、音声、数値と多岐に渡るため、活用の幅も広いと言えるでしょう。
一方ビジネスで適切に使いこなすには、基本的な知識を抑えておくことも重要です。この記事では、「ディープラーニングとは」を解説していきます。
人工知能と機械学習、ディープラーニングの違い[1]
AIについて触れるメディアでは、「人工知能」と「機械学習」「ディープラーニング」という似て非なる用語が飛び交っているため、混乱してしまう方も少なくないでしょう。
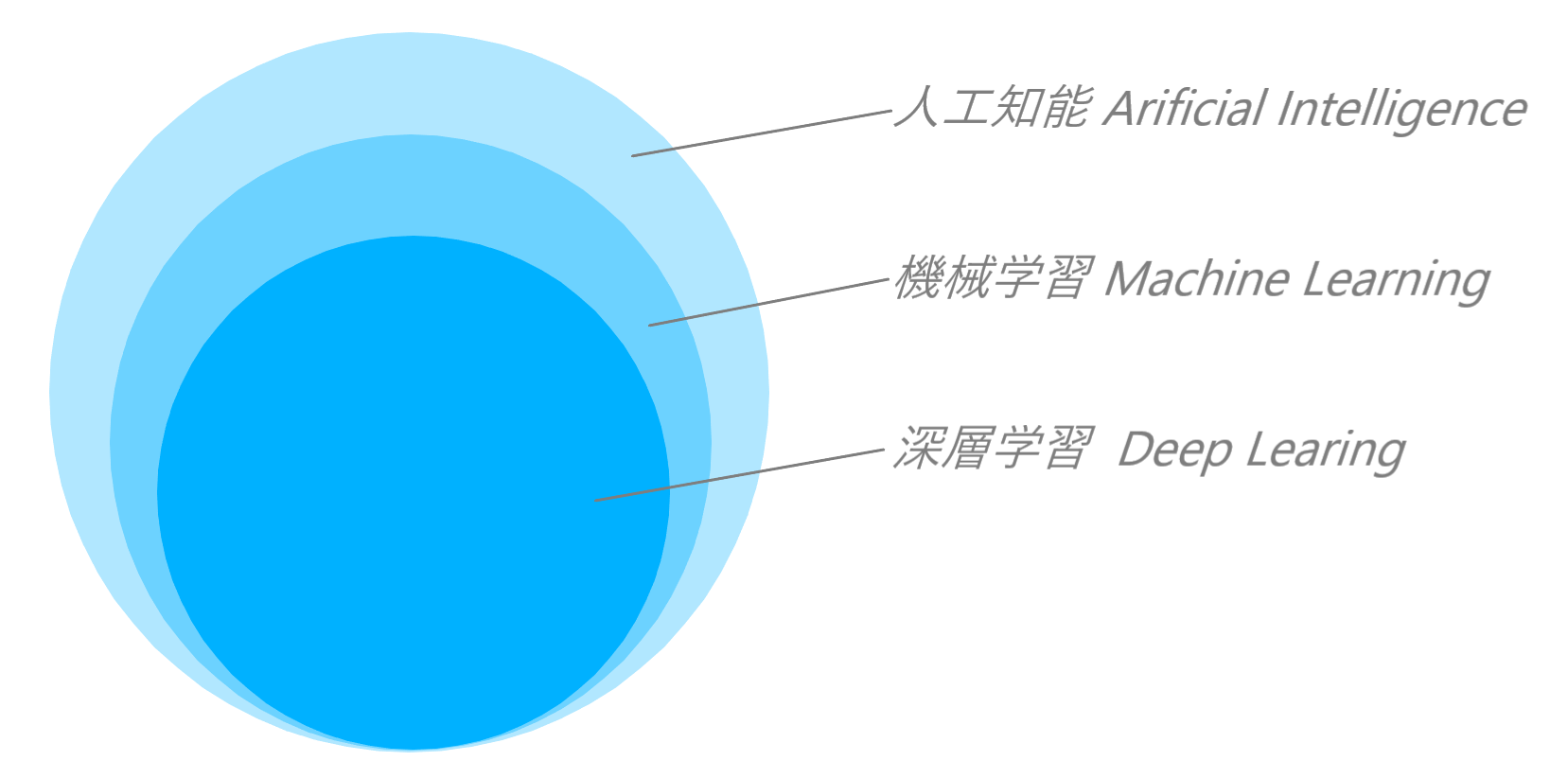
3つの関係性について、大まかな関係性は以下の図1のようになります。

図1 人工知能、機械学習、ディープラーニングの関係性
まず人工知能とは学習や推定、判断といった人間の知能的活動をコンピューターによって再現するための技術です。
機械学習はこの人工知能の一種になります。機械学習では、特定の物事に関する大量のデータをコンピューターに読み込ませることで、裏側に潜むパターンを学習させます。そして学習済みの機械学習モデルにデータを入力すると、それに対して何らかの推定や判断を実施して結果を出力するのです。
ディープラーニングは機械学習の一種です。機械学習の場合は、学習の起点となる何らかの特徴を人間が定義してあげる必要がありますが、ディープラーニングはそれを自動的に見つけることができる、という点が大きな違いです。
これにより一般的に人間では気付かないような特徴を発見し、推定や判断を行えるので、より精度が高くなると考えられています。しかし、その認識する仕組みはブラックボックスとなっているため、どのように認識しているか知ることはできません。また必ずしもディープラーニングを用いれば精度が高くなるとも限りません。
ディープラーニングの仕組み[2][3][4]
ディープラーニングの仕組みを知るためには、まず機械学習に用いられるアルゴリズムの一種であるニューラルネットワークについて理解しなくてはなりません。ディープラーニングを含む機械学習の根本的な概念になるからです。
ニューラルネットワークとは人間の脳のシステムを模したコンピュータシステムを指します。人間の脳にはニューロンと呼ばれる神経細胞が何億も存在します。これらのニューロンは、脳に入力された信号を処理して、何らかの情報を出力する役割を互いに連携しながら担っています。
このようなニューロンが多く集まった多階層構造がニューラルネットワークになります。
ニューラルネットワークの層は主に、
・入力層(データ・信号が入力される層)、
・隠れ層(入力されたデータの特徴を重要度に応じて重みづけし、計算・処理する層)、
・出力層(処理されたデータを出力する層)
の3層で構成されています。

図2 ニューラルネットワークの例。入力層(黄色)、隠れ層(青)、出力層(赤)で構成されている。[5]
このうち隠れ層は、入力されたデータの特徴を抽出できるように、複数の層で構成されています。
そして特に深い層を持ったモデルに用いた手法がディープラーニングです。またニューラルネットワークの中でも、ディープラーニングで用いられるタイプをディープニューラルネットワークと呼びます。
隠れ層の階層が従来のモデルよりも深いため、より細かく特徴を抽出し、精度の高いモデルを作ることができるのです。一方で計算量が増えるので、処理時間も増えてしまうというデメリットもあります。
またディープラーニングにも複数のアルゴリズムが存在し、用途に応じて使い分けることになります。ベーシックなアルゴリズムを2つご紹介します。
そのうちの一つ、畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)は、画像に強いとされています。
畳み込み(Convolutional)とは、ある関数を元の関数に対して平行移動させながら重ね、足し合わせることを意味します。画像の場合、元の画像に対して小さなフィルターをずらしながら見ていき、それぞれの特徴を順番に抽出していきます。
もう一つは、再帰型ニューラルネットワーク(Recurrent Neural Network、RNN)。これは主に時系列データのような、連続性のあるデータに対して用いられます。応用分野としては自然言語処理などがあげられます。
ここで具体例を使ってディープラーニングの仕組みを説明します。
例えば多くの自動車の中から、特定の車種を自動で判別できるシステムをディープラーニングによって作るとします。ディープラーニングのアルゴリズムは、画像認識に強いCNNを用います。
まずは、学習データの用意です。
この例の場合、自動車会社の車種ごとに大量の画像を集め、それぞれの画像に車種を表すラベルを付けます。
この学習用のデータをディープラーニングモデルに与えると、様々な特徴を自動で抽出し、学習することができます。この学習作業は、作成したモデルが必要とする精度で車種を推定できるようになるまで行います。こうしてモデルが完成すれば、あとは実用フェーズとなります。

図3 ディープラーニングを用いた車種の推定
ディープラーニングのビジネス活用状況と課題
ビジネスのどの分野においても、ディープラーニングの活用はまだ始まったばかりと言えるでしょう。そのため実用に向けた課題も多くあります。
例えば機械学習・ディープラーニングを使いこなすには、関連するデータが重要になってきます。しかしこれまでデータを記録していなかったり、記録していても紙媒体でしか残っていなかったりといった問題に直面している企業も少なくありません。
そのため実際に使えるデータの収集・整理から始まるケースが多いというのが現状でしょう。ビジネスでのディープラーニング活用の起点になるデータ。その種類ごとに概要と弊社事例を紹介します。
画僧データの概要と事例

先程の車種推定の例のように、物事のビジュアルをもとに分類や判別を行う場合では画像データが用いられます。
ちなみに画像データとは、主にカメラで撮影された写真だけでなく、動画データも該当します。
インターネットの普及により、画像データが非常に収集しやすくなっていることもあり、最も発展している分野になります。
弊社が手掛けた事例として、ディープラーニングによって農作業の効率化を図った施策をご紹介します。
本事例はトマトの実・蔕(へた)・枝・幹を自動で認識できる技術です。カメラで撮影した画像を元に、リアルタイムで判別できます。
この技術をベースに、自動収穫ロボットや、実の熟度や腐植土の測定などへの応用が可能となります。現在は自動収穫ロボット導入に向けて進めているところです。
数値データの概要と事例
画像データと同じく、数値データも大量に存在し、取得が容易であることから、比較的発展している分野です。
主に物事が起こる確率や数値の動きに関する予測に用いられることが多く、例として病気の発症率や株価の予測等があります。
実践する上でのよくある問題として、数値データが正しく記録されていない、数値以外のデータも混ざっている、といった事情により、ディープラーニングに適さないデータしかない、というケースもあります。
そのため目的に応じて、数値データを適切に収集・記録していくことが重要です。
弊社では製造業のクライアント向けに、製品の品質予測を行うモデルを開発しました。リアルタイムで製造工程のデータを収集し、不良品ができそうだと事前に予測できれば、何等かの方法でアラームし、未然に防ぐことが可能になるのです。学習データとして、製造工程の機械の温度やモーターの速さ、その時の条件でできた製品の品質データをモデルに与えました。
テキストデータの概要と事例

テキストデータの活用は、近年のSNSの爆発的な普及によって注目され始めているジャンルです。
製品やサービスに関するSNS上の口コミを分析することによって、品質や施策の改善につなげるといった例が目立ちます。
テキストデータを使ったディープラーニングでは、言葉そのものだけでなく周辺の文脈も考慮して、正確に意味を把握することが精度向上のカギを握ります。
弊社では、テキストデータを元に、医療向けのディープラーニングモデルを手がけました。
このモデルは、SNSなどのチャット対話の履歴を分析することで、投稿者の症状を判別できるというものです。あらかじめモデルには、投稿内のテキストや前後の文脈をもとに症状を判断できるように学習させます。最終的には、その症状に合った専門医をレコメンドするというシステムです。
音声データの概要と事例
最後に音声データの紹介になります。
音声認識の技術は主に次の2段階に分かれています。
・音声を認識しテキストに変換する段階
・変換されたテキストの内容を理解する段階
そのため、テキストデータの延長線上にある技術とも言えます。
音声の意味を判別するには、方言やアクセントなどの考慮をする必要があるほか、省略語や本来の意味とは違った使い方をされる言葉も認識できる必要があるなど、精度の向上が非常に難しい分野です。
現状の実用化範囲も、音声検索のように、比較的短い言葉が中心となるシーンに限られます。
例えば「ヘイ、シリ! 今日の天気。」は基本的に間違うことはないが、「ヘイ、シリ!明日の東京都渋谷区○○X丁目Y番地Zの何月何日の天気を教えて」と長くなれば精度は落ちてしまうでしょう。
弊社が手掛けた施策として、コールセンターにおける活用例があります。電話をかけてきたお客様の音声を認識し、その質問に応じた適切な返答を、コールセンター職員のパソコンに表示するというシステムです。そのコールセンターの課題であった、職員の経験の差による対応レベルの違いを解消することに成功しました。
参考文献
[1] 「ディープラーニング(Deep Learning)とは?【入門編】」, LEAPMIND BLOG, 2017年6月16日
http://leapmind.io/blog/2017/06/16/ディープラーニング(deep-learning)とは?【入門編】/
[2] 「AI(人工知能)とは?誰でも簡単にわかるディープラーニングの仕組み」,
AI研究所, 2018年1月24日
[3] 「深層学習(ディープラーニング)を素人向けに解説(前編)- 基礎となるニューラルネットワークについて」, Stone Washer’s Journal, 2015年3月5日
[4] 「ニューラルネットワークの基礎を初心者向けに解説してみる」, ロボット・IT雑食日記, 2018年6月20日
https://www.yukisako.xyz/entry/neural-network
[5] edit image
http://editimage.club/rapic.html