こんな使い方もあった、チャットボットのユニークな活用事例集

Incubit Blog Team

目次
ビジネスやテック系のニュースで、引き続きチャットボットが日々話題になっています。
こういうテクノロジー系のメディアをやっていると、つい目新しい部分、つまり「技術的にこんなこともできるようになった!」「この業界でもついにチャットボットを導入!」といった点に注目したくなってしまいます。
けれどもそもそもチャットボットは何らかのユーザーニーズを満たすための手段です。そうなると目新しい技術だけ騒いで終わりになってしまうのは、少し違う気もしてしまいます。ユーザーニーズを最も適切に満たす手段が、最も洗練された技術である必要は必ずしもないからです。
たとえばメルマガというチャネル。ネット黎明期からある古い情報発信手段ですが、検索技術が洗練され、SNSが登場した今になっても、存在感がますます増しています。メルマガにしか満たせないユーザーニーズ(関心の高い情報源による発信をタイムリーに確実に受け取りたい)があるからです。
チャットボットもまた同じかなと思います。まだぎこちないやりとりしかできないですが、うまく使えば効果は絶大なはず。「うまく使う」というのは、「自社のユーザーの悩み事は何か?」「それを解決するための手段とは?」という視点で、チャットボットを活用すること。
今回はチャットボットの事例集をお届け。特別な技術は使っていないけれども、ユーザーの課題解決を念頭に、絶妙なベネフィットを提供している施策例です。チャットボットの使い道は本当に多種多様だなと思わされます。
■イヤな男をシャットダウン、女性の味方のチャットボット
最初の事例は、出会い系サイト向けのボット「Ghostbot」です。
出会い系サイトを使う女性にとって、悩みの一つがデリカシーのない男とのやりとり。自分が相手にされていないと感じると罵声を浴びせかけたり、ひいては卑猥な画像を送りつける輩もいたりします。こういうシチュエーションにも対処しないといけないとなると、出会い系サイトを使う女性にとってはストレスでしょう。
そんな時に役立つのがGhostbot。女性が「あ、この男ダメだ」と思った瞬間に、以下のような設定一つで相手とのやりとりをボットが代わりに担ってくれるというもの。

Ghostbotの役割は、相手との会話を自然に終わらせること。これ以上メールを続けたくないという旨をやんわりと伝えてくれるそう。Ghostbotのプロダクトデザイナーいわく、「会話を盛り下げて、エンゲージメントを下げる」よう設計されているとのこと。

出会い系サイトでのやりとりにおいて、ボットが自動で返信できるようにするためには、元となる学習データが必要です。そのためGhostbotの担当者は、ネット上にアップされている(さらされている?)出会い系でのやりとりをかき集めたといいます。
一例がByeFelipeというインスタグラムのアカウント。ここには出会い系で逆上した男どもによる、女性へ罵倒メッセージのキャプチャがアップされています(彼らもまさかこんな形でネット上にさらされるとは思っていなかったでしょう)。
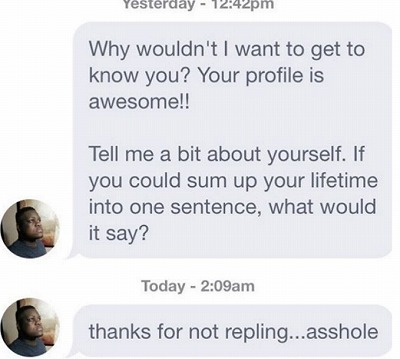
面倒な会話を自分で終わらせなくてはいけない、もしくはブチっと切ってしまうとなると面倒ですが、あとはボットがやってくれると思えば気が楽になりそうです。
■ AI弁護士、複雑な法的手続きが一瞬で
英BBCから「ネット界のロビンフット」と称された期待のスタートアップDoNotPay。同社は一般人では難しい様々な法的手続きを自動で担ってくれるチャットボットを提供しています。
創業者は若干20歳でスタンフォード大学に通うJoshua Browder氏。18歳の時に30枚以上の駐車違反切符をきられたことがDoNotPayを立ち上げたきっかけだったといいます。
交通違反切符は、適切に申請すれば取り消してもらえる可能性がありますが、必要な法的手続きを個人でやるのは至難の業。DoNotPayのチャットボットを使えば、いくつかの質問に答えるだけで、1分ほどで申請書が出来てしまいます。

DoNotPayによって取り消された違反切符は、イギリスだけでも約17万5000件(16年末時点)。金額にすると約5億6000万円に上るといいます。
現在は違反切符の取り消しだけでなく、遅延した飛行機や電車の補償請求、ホームレスの住宅申請、HIV患者への法的アドバイス、難民申請などにも対応しています。
根底にあるのは、複雑な法的手続きをチャットボットが肩代わりすることで、市民が本来受けられる権利を享受できるようにしようという考えです。
複雑で面倒な手続きを肩代わりするというスタイルは、今後チャットボットのあるあるパターンの一つになりそうです。
■投票率を上げろ、面倒な有権者登録を肩代わり
これも同じく面倒な作業を肩代わり系のチャットボットです。有権者登録をチャットボットがやってくれるというもの。
アメリカの大統領選挙に投票するには、各州のルールに則って有権者登録をする必要があります。ただこの手続きが非常に面倒らしく、投票率を下げる要因になっています。
たとえば2012年の大統領選挙では、有資格者のうち30%以上が有権者登録をしていなかったとのこと。さらに18~24歳の若年層に限ると、この割合はさらに上がるそう。
そこでFight for the FutureというNPOが制作したチャットボット”HelloVote”では、いくつかの質問に答えるだけで、1~2分で手続きを完了できるようになっています。
氏名や住所、生年月日、運転免許情報などの個人情報を入力することで、州の有権者データベースに登録される仕組みです(ただしオンラインでの登録を認めていない州もあるので、一部郵送などのステップが入る地域もあり)。
ターゲットはスマートフォンに慣れ親しんだ若年層。モバイルのテキストメッセージやFacebookメッセンジャー上にてチャットベースで手続きできるので、従来の書類手続きよりかなり敷居は下がりそうです。
ただ投票率を下げている要因には、手続きの煩雑さに加えて、費用の問題もあります。最大で約7000円の費用がかかる州もあるため、貧困層による投票率に悪影響を与えているよう。
チャットボットだけで全て解決というわけにはいかなそうですね。
■有料購読の管理キャンセル
毎月費用がかかる有料サービスの管理って、地味に大変だったりしますよね。
通信サービスのオプションをキャンセルしたと思っていたけれども、実はできておらず毎月数百円引かれていた、なんてこともありがちです。
チャットボットのTruebillでは、銀行口座もしくはクレジットカード情報をもとに、Netflixやスマホの通信費、スポーツジムのメンバーシップといった有料サービスを抽出。一覧化して管理できることに加えて、キャンセルもボット上でできてしまいます。

ターゲット層は、お金の管理が苦手なルーズな人が主になってきそうです。となると、慣れ親しんだプラットフォーム(Facebookメッセンジャーなど)でチャットによって完結できるという手軽さは、非常に良さそうです。
■ボットを通してユーザー調査
上記の事例とは少し毛色が違う施策です。
米デザインコンサル大手のIDEOは、ユーザー調査の手段としてチャットボットを活用。そこで得た知見を製品デザインに活かしているとのこと。
一例として挙げられているのが、日本の電機メーカーとの協業。2014年に運動する女性向けのウェアラブルデバイスとスマホアプリのデザインに携わったそう。ユーザーによる日々の行動をトラッキングして得たデータをもとに、フィットネスに関するアドバイスを提供するというもの。
ここで問題になってくるのが、ターゲット層(35~54歳のアメリカ人女性)はフィットネス向けのウェアラブルデバイスに何を求めるのか?という点。従来の男性向け製品のように、走行距離のようなデータの優劣を他のユーザーと競う、というベネフィットでは女性が満足できません。
そこで彼女たちのニーズを探るためのプロタイピングツールとして、IDEOはボットを開発。被験者の女性がランニング中に、様々なメッセージを送りました。
たとえば「素晴らしいワークアウトです。この調子でいきましょう」「1万歩まであと5分です」といった具合です。
ボットを通して彼女たちの反応を観察した結果、やはり男性とは違うニーズがみえてきました。フィットネスデータで優劣を競いたがる男性に対して、女性の場合は自身のアクティビティにまつわるストーリー全体をシェアしたい、という傾向があったそう。
たとえば疲れて途中でワークアウトをやめてしまった、甘い物に手を出してしまったなどの失敗談も含めて、コミュニケーション手段としてシェアしたがったとのこと。
ターゲットの反応をリアルタイムで吸い上げる手段として、チャットボットをうまく活用した事例といえるでしょう。

■履歴書替わりにチャットボット
最後は、求職者がチャットボットによって自身の経歴をアピールした事例。チャットボットを通じて、採用担当者が彼女の経歴や実績を閲覧できるようにしたのです。「求職者に関する情報を知りたい」という企業側のニーズに応えた一例です。
ボットを作ったのは、サンフランシスコ在住のマーケター、Esther Crawfordさん。彼女はエンジニアではなく、HTMLやCSS、JSの基礎知識がある程度。そのためTextItのようなプログラミングなしで構築できるツールを使ってボットを作ったといいます。
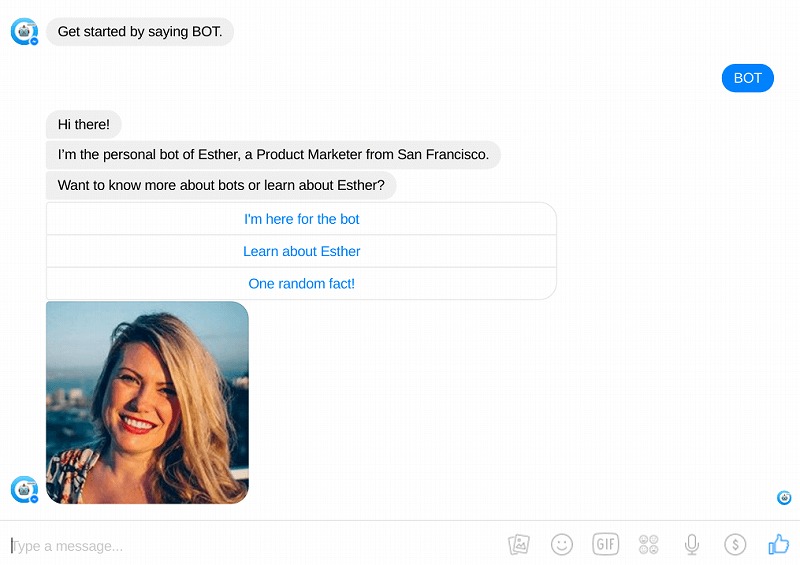
求職者が自身の経歴をボットでアピールする斬新さが話題となり、2万4000件ものメッセージをやりとりするに至ったそう。その中にはFacebookやGoogle、Microsoftなどの大手も含まれていたといいます。
チャットボットが話題になり始めた旬な時期だっただけに、彼女のマーケターとしてのセンスやテクノロジーへの理解を強烈にアピールできた結果といえるでしょう。